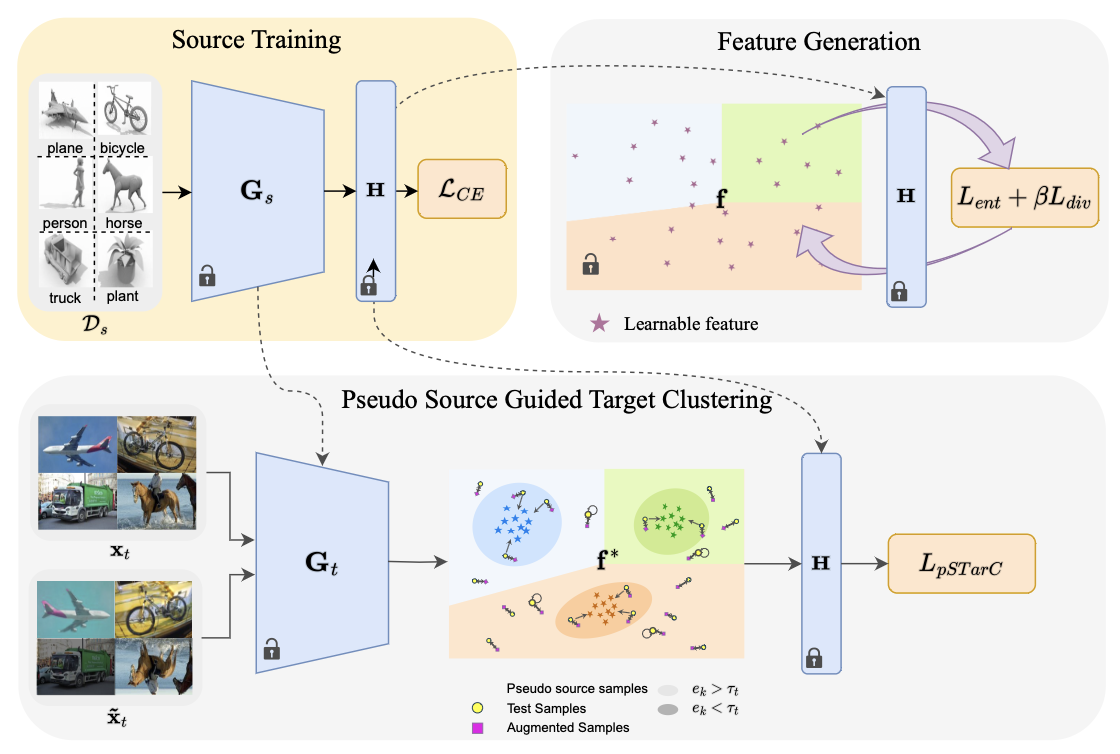
In Test-Time Adaptation (TTA), a model trained on source domain \(\mathcal{D}_s\) must adapt to a target domain \(\mathcal{D}_t\) at inference time, without access to source data or ground truth labels. In the more challenging Continual TTA (CTTA) setting, the target distribution shifts continuously over time: \(P_t^{(1)} \neq P_t^{(2)} \neq \ldots\).
Existing TTA methods typically require the source data to compute statistics or rely on batch normalization updates that become unstable at small batch sizes. pSTarC addresses these limitations by operating in the fully test-time protocol: no source data, no labels, no offline statistics — adapting purely from the test stream.
Key challenges addressed:
- Source-free setting: No access to source data or source model internals beyond the final classifier.
- Real-world domain shifts: Benchmarks include domain shifts across artistic styles, object categories, and image corruptions.
- Memory efficiency: pSTarC maintains only a compact pseudo-source feature buffer (0.03M), vs. 4.67M for AdaContrast.