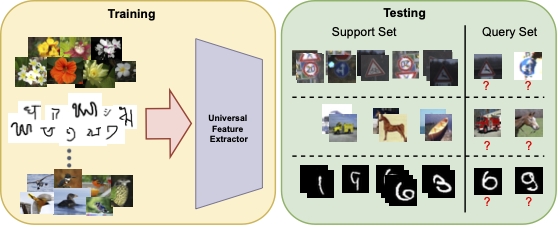
Cross-Domain Few-Shot Learning
In CD-FSL, a universal feature extractor \(F\) is trained on labeled data from multiple source domains \(D_\text{train}\). At test time, it must adapt to N-way K-shot tasks sampled from unseen classes in unseen domains \(D_\text{test}\). Each task \(\mathcal{T} = (\mathcal{S}, \mathcal{Q})\) consists of a labeled support set \(\mathcal{S}\) and an unlabeled query set \(\mathcal{Q}\).
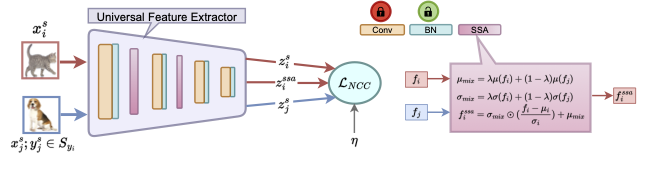
Most state-of-the-art methods (FLUTE, URL, TSA) handle this by introducing task-specific learnable modules, which either increase model parameters or change the trained architecture. This is undesirable in many practical settings. SSA-BNS addresses CD-FSL without any architectural changes or extra parameters, by revisiting two under-explored components: BatchNorm adaptation and the cosine similarity scale factor.