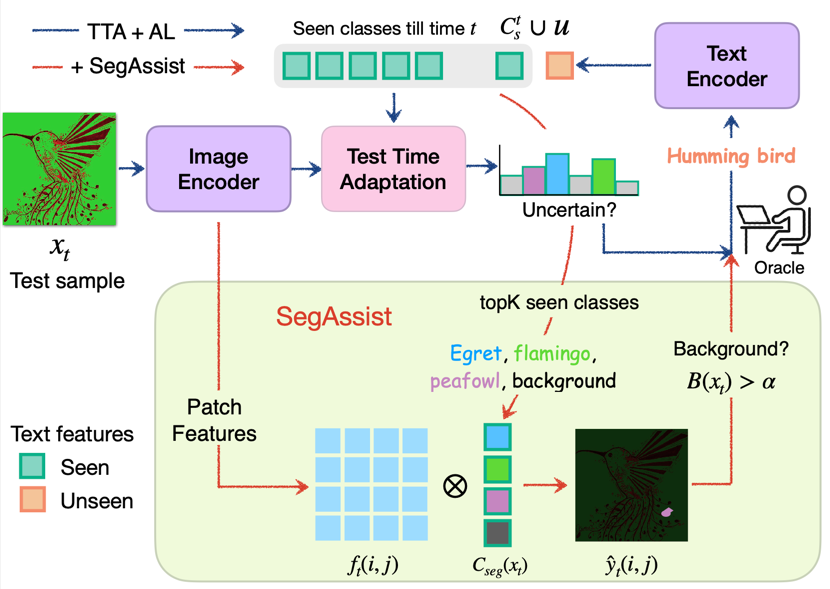
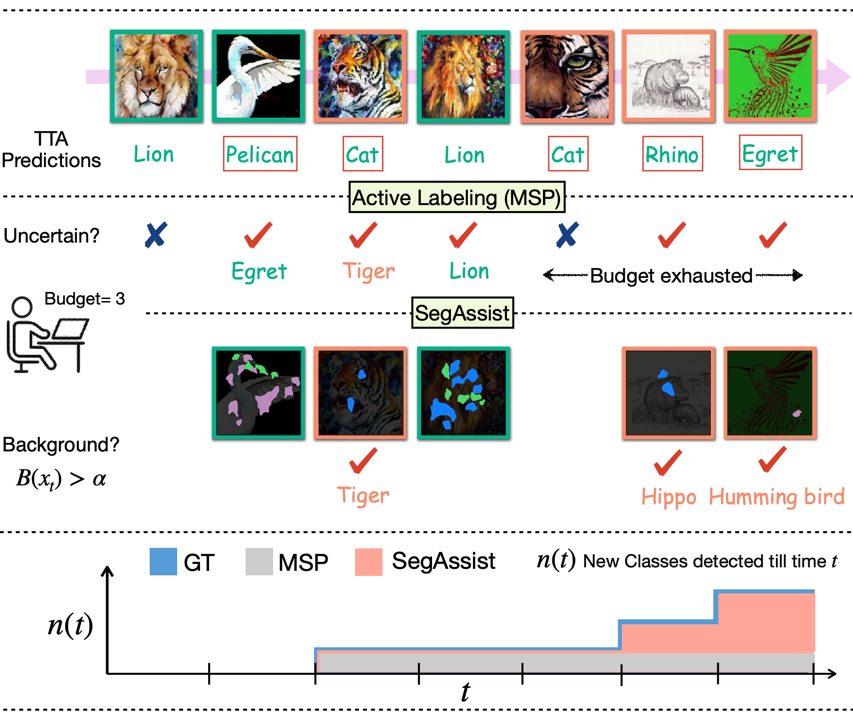
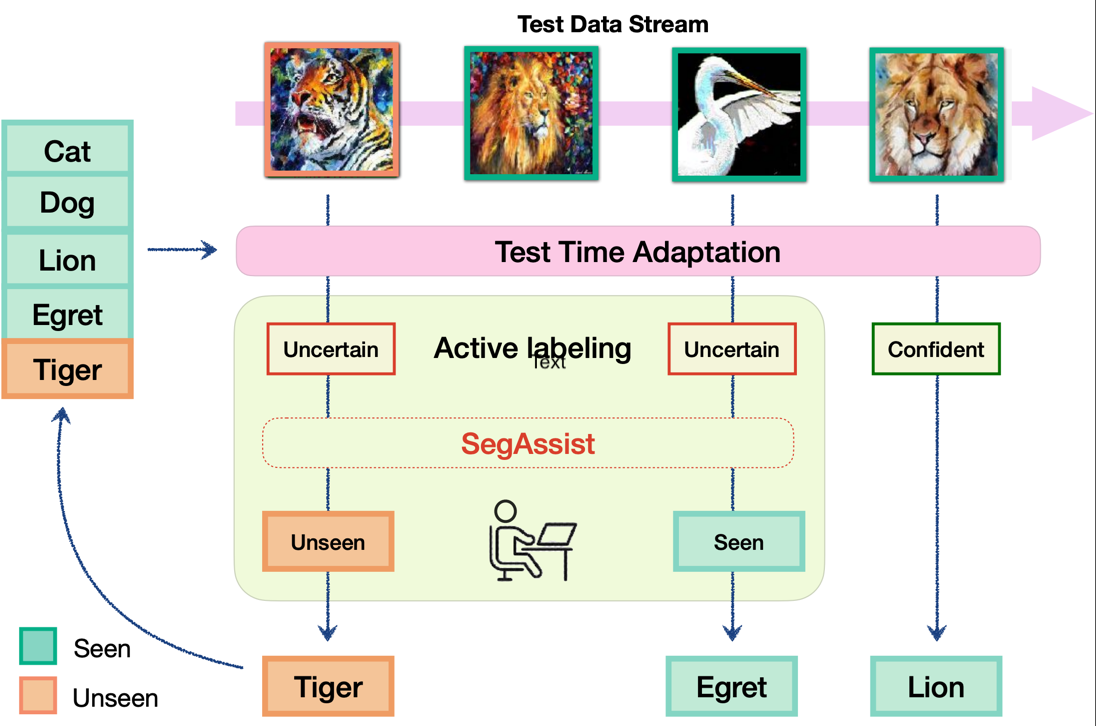
Incremental Test Time Adaptation
Consider a model deployed in the real world, navigating a dynamic environment where it encounters familiar objects in unfamiliar settings and new objects it has never seen before. Traditional TTA methods handle covariate shifts but cannot accommodate dynamically emerging new classes. We introduce ITTA, a protocol that requires the model to simultaneously:
- Continuously adapt to covariate shifts
- Recognize and incorporate new classes as they appear
- Operate on a single-image basis without access to batches or labeled data
- Maintain performance across seen classes and a growing set of dynamically incorporated unseen classes
The table below situates ITTA among closely related research directions. ITTA is the only setting that handles all of: training-free adaptation, single-image testing, covariate shift, label shift, and a growing classification space \(\mathcal{C}_s + \mathcal{C}_u\).
| Training-free | TTA | Covariate shift | Label shift | Single image | Task space | Methods |
|---|---|---|---|---|---|---|
| ✗ | ✓ | ✓ | ✗ | ✗ | \(\mathcal{C}_s\) | TENT, CoTTA, ROID |
| ✓ | ✓ | ✓ | ✗ | ✓ | \(\mathcal{C}_s\) | TPT, TDA, DPE |
| ✗ | ✓ | ✓ | ✓ | ✗ | \(\mathcal{C}_s+1\) | Open-world TTA |
| ✓ | ✗ | ✗ | ✓ | ✗ | \(\mathcal{C}_s+\mathcal{C}_u\) | Class Incremental Learning |
| ✓ | ✓ | ✓ | ✓ | ✓ | \(\mathcal{C}_s+\mathcal{C}_u\) | Proposed ITTA (Ours) |
Table 1. Comparison of the proposed ITTA framework with existing research directions.