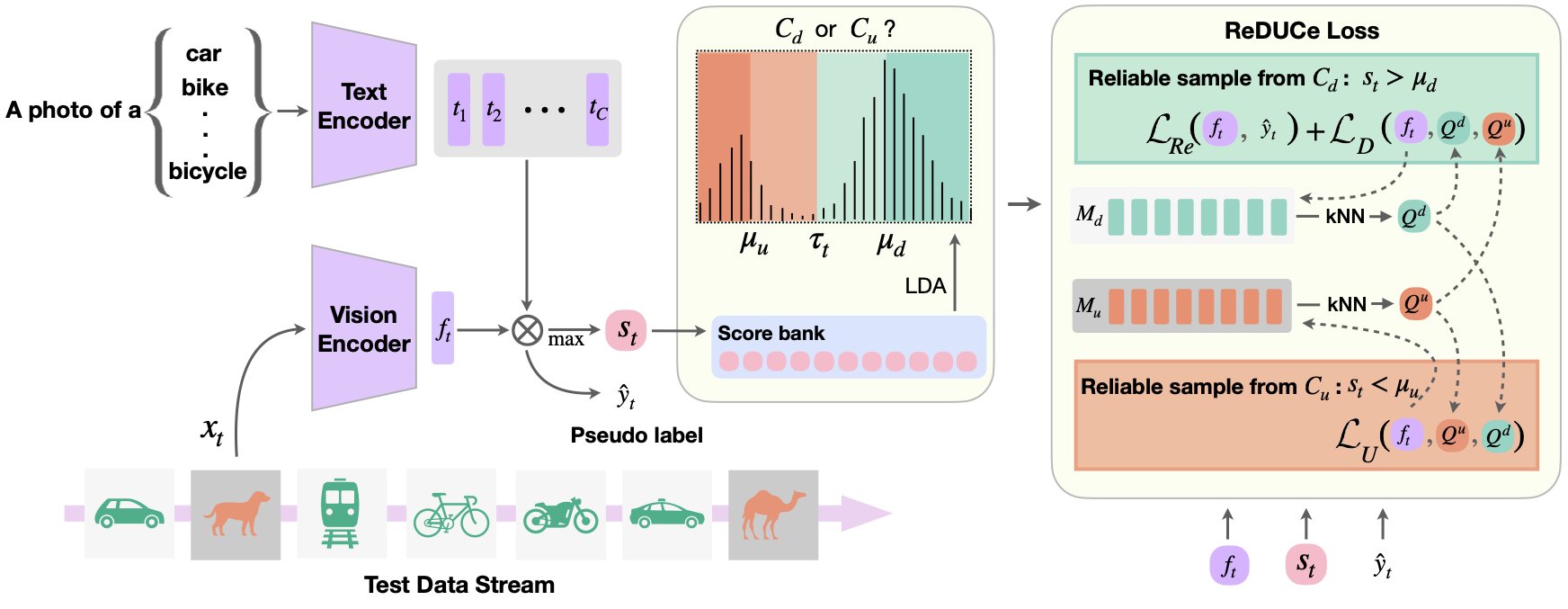
We consider Open-set Single-image Test-Time Adaptation (OSTTA): at each time step \(t\), a single test sample \(x_t\) arrives from a stream \(\mathcal{D}_t = \mathcal{D}_d \cup \mathcal{D}_u\) comprising:
- Desired class samples \(\mathcal{D}_d\): from one of the \(|\mathcal{C}_d|\) known classes, potentially under domain shift.
- Undesired class samples \(\mathcal{D}_u\): from unknown classes \(\mathcal{C}_u\), with \(\mathcal{C}_d \cap \mathcal{C}_u = \emptyset\) (semantic shift).
The goal is to perform \(|\mathcal{C}_d| + 1\) way classification at each step: identify whether \(x_t\) is a desired class sample, and if so, classify it correctly; otherwise predict "I don't know." Unlike prior TTA work, there is no batch, no source data, and no ground-truth labels — the model must adapt on a single image at a time under a continuously shifting mix of domain and semantic shift.
We evaluate under four OSTTA scenarios:
- Single domain: desired samples from one unseen domain + undesired samples.
- Continuously changing domains: desired domain shifts over time.
- Frequently changing domains: very few samples per domain.
- Varying sample ratio: different proportions of desired vs. undesired samples.