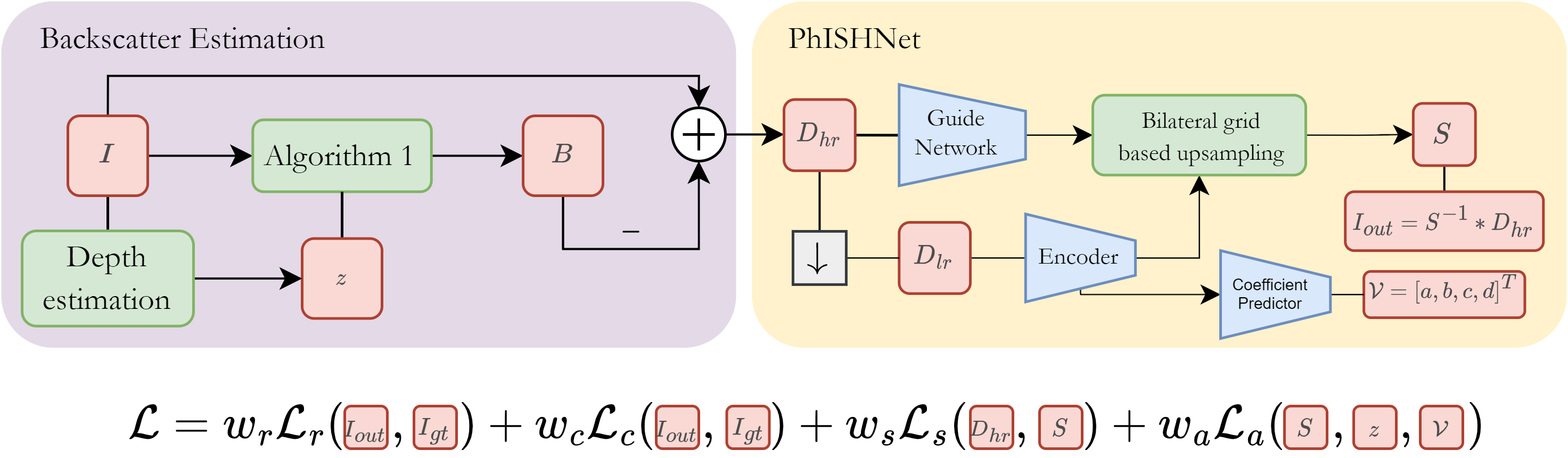
We first estimate and remove the backscatter component \(B\). The depth map \(z\) is obtained from an off-the-shelf monocular depth estimator (boosted MiDaS). The depth map is partitioned into 10 evenly spaced clusters; within each cluster, the darkest 1% of RGB triplets (where \(I \approx B\)) are collected into set \(\Omega\). An overestimate of backscatter is \(\hat{B}(\Omega) \approx I(\Omega)\), which follows:
\[ \hat{B} = \underbrace{J' \cdot e^{-\beta_{d'} z}}_{\text{Residual}} + B^\infty(1 - e^{-\beta_b z}) \tag{3} \]
The coefficients \(B^\infty, \beta_b, \beta_{d'}, J'\) are estimated by non-linear least squares fitting. The direct signal is then \(D_c = I_c - \hat{B}_c\).
The direct signal \(D\) resembles a low-light underexposed image. Following the retinex model, we decompose \(D = S \ast \tilde{I}\) where \(S\) is the illumination map and \(\tilde{I}\) is the reflectance (enhanced image). PhISH-Net predicts a 3-channel illumination map \(S_{hr}\) from which the enhanced image is obtained as \(I_{out} = D_{hr} / (S_{hr} + \epsilon)\).
The network uses a lightweight convolutional encoder to extract features at low resolution. Local and global features are then used to predict bilateral grid coefficients, which are applied to a full-resolution guide map to produce \(S_{hr}\). This keeps most computation at low resolution while generating high-resolution outputs.
To couple the deep enhancement with the physics of the UIFM, we introduce a novel loss that constrains the predicted illumination map to respect the known behavior of the attenuation coefficient \(\beta_d\). A coarse estimate of \(\beta_d\) can be derived from the predicted \(S_{hr}\) and depth \(z\):
\[ \hat{\beta}_d(z) = \frac{-\log S_{hr}}{z} \tag{4} \]
Sea-Thru established that \(\beta_d\) follows a two-term exponential decay with depth:
\[ \beta_d(z) = a \cdot e^{-b \cdot z} + c \cdot e^{-d \cdot z} \tag{5} \]
The wideband attenuation prior loss enforces this relationship:
\[ \mathcal{L}_a = \left\|\frac{-\log S_{hr}}{z} - (a e^{-bz} + c e^{-dz})\right\|^2 \tag{6} \]
The coefficients \(V = [a, b, c, d]\) are predicted by a learnable network from encoder features. The total training loss combines reconstruction, color, smoothness, and attenuation prior:
\[ \mathcal{L} = w_r \mathcal{L}_r + w_c \mathcal{L}_c + w_s \mathcal{L}_s + w_a \mathcal{L}_a \tag{7} \]
with \(w_r = 10,\ w_s = 2,\ w_c = 1,\ w_a = 0.5\).