Source Model as a Domain Shift Detector
We observe that the feature extractor of the source-trained model naturally encodes domain-specific information. For a batch of test samples \(x_t = \{x_1, \ldots, x_N\}\) at time \(t\), we compute the mean feature vector:
\[ \mathbb{E}[v_f(t)] = \frac{1}{N} \sum_{k=1}^{N} f(x_k) \]
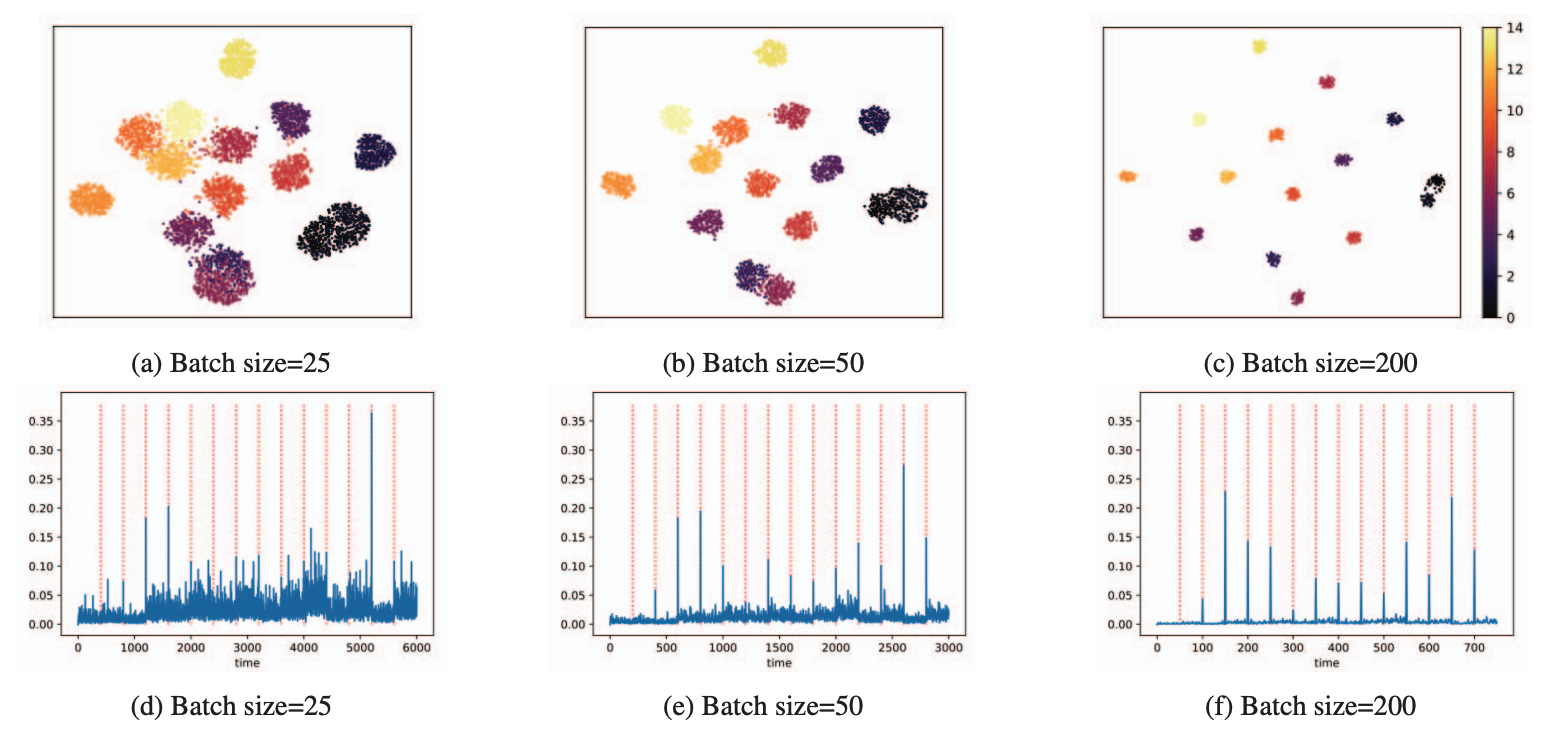
As batch size increases, the class-specific component of the mean averages out, leaving the domain-specific component dominant. This makes the mean feature a reliable proxy for the domain identity of the batch.
Domain Shift Signal (DSS)
We define the Domain Shift Signal as the cosine dissimilarity between the mean features of consecutive batches:
\[ \text{DSS} = 1 - \cos\!\left(\mathbb{E}[v_f(t)],\; \mathbb{E}[v_f(t-1)]\right) \tag{1} \]
When consecutive batches come from the same domain, DSS is low. When a domain shift occurs, the mean features diverge and DSS spikes.
Domain Shift Detector (DSD)
To robustly detect shifts, we compute a moving average of DSS and define the detector as:
\[ \text{DSD} = \mathbb{1}\!\left\{\text{DSS} > k \cdot \text{MovAvg}(\text{DSS})\right\} \tag{2} \]
where \(k = 3\) across all experiments. When DSD fires, the model is reset to the source checkpoint, allowing the underlying TTA method to restart adaptation on the new domain.
Algorithm
The DSS module is entirely decoupled from the choice of TTA method. It wraps any single-domain TTA method (TENT, AaD, EATA, etc.) and converts it into a continual TTA method:
- For each incoming batch, compute the mean feature vector using the fixed source feature extractor.
- Compute DSS as cosine dissimilarity with the previous batch's mean feature.
- If DSD fires (DSS exceeds adaptive threshold): reset model to source checkpoint and reset optimizer state.
- Continue with standard TTA adaptation on the current batch.
This approach is computationally cheap: it adds only a single forward pass through the frozen source feature extractor per batch, with negligible memory overhead.